Creating test data for Apache Cassandra cluster
In many cases you are required to generate test data for Cassandra to do various type of testing. Read the rest of the blogpost if this is something you need and at the end, you should be able to create some test data very quickly.
I use the Ubuntu 16.04.2 LTS and Apache Cassandra 3.0 for this testing. The Cassandra cluster that I’m using here is deployed on AWS but this should not be a consideration factor for test data creation.
Use the steps mentioned below to create the test data.
- Download the csv file
curl -O http://samplecsvs.s3.amazonaws.com/Sacramentorealestatetransactions.csv
Note. You can download this file directly on to the EC2 but due to some formatting issue it did not work correctly for me. I downloaded the file to my local machine (Mac) first and then opened the file using TextEditor then copied the contents to the EC2.
- Create the csv file on EC2
I just used the vi editor to open a new file called, realstatesdata.csv and then pasted the file contents (including headers) that I copied in step #1. Save the file. (You should be familiar with the VI editor to perform this step.)
After completing this step, you now have “realstatesdata.csv” on EC2.
- Connect to the Cassandra cluster using cqlsh

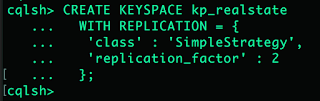
- Create a Keyspace
You need to create a Keyspace (in general terms, a database) which is a high level hierarchical object to contain Cassandra tables. The keyspace name I’ve chosen is “kp_realstate” but feel free to have any name which you want.
- Create a table
You also need to have a table which is the actual object which contains your real data. Unlike MongoDB, you need to have a the table schema created before you insert any data. I already analyzed the data set in csv file we just downloaded and decided the columns based on that. The table name is “realestate_data” again its your choice.
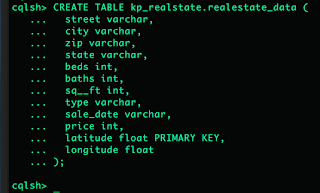
Note that, the order of the columns in CREATE TABLE statement should be the same as the order it appears in the csv file.
- Load the data
You use the COPY command to load data from a file to Cassandra.
COPY kp_realstate.realestate_data (street,city,zip,state,beds,baths,sq__ft,type,sale_date,price,latitude,longitude) FROM 'realstatesdata.csv' WITH HEADER = TRUE;
It has to be executed at CQL prompt.
If the import is successful you will see the messages like below.
Processed: 985 rows; Rate: 1151 rows/s; Avg. rate: 1865 rows/s
985 rows imported from 1 files in 0.528 seconds (0 skipped).
- Make sure the data is imported successfully
At CQL prompt, you can execute any of the statements below.
select count(*) from kp_realstate.realestate_data;
select * from kp_realstate.realestate_data limit 30;
At the end, you’ve full data set for your testing.